Image by Author
This tutorial will discuss leveraging Python’s capability to execute multithreading and multiprogramming tasks. They offer a gateway to perform concurrent operations within a single process or across multiple processes. Parallel and concurrent execution increases the speed and efficiency of the systems. After discussing the basics of multithreading and multiprogramming, we will also discuss their practical implementation using Python libraries. Let’s first briefly discuss the benefits of parallel systems.
- Improved Performance: With the capability to perform tasks concurrently, we can reduce the execution time and improve the system’s overall performance.
- Scalability: We can divide a large task into various smaller sub-tasks and assign a separate core or thread to them for their independent execution. It can be helpful in large-scale systems.
- Efficient I/O Operations: With the help of concurrency, the CPU doesn’t have to wait for a process to complete its I/O operations. The CPU can immediately start executing the following process until the previous process is busy with its I/O.
- Resource Optimization: By dividing the resources, we can prevent a single process from taking up all the resources. This can avoid the problem of Starvation for smaller processes.
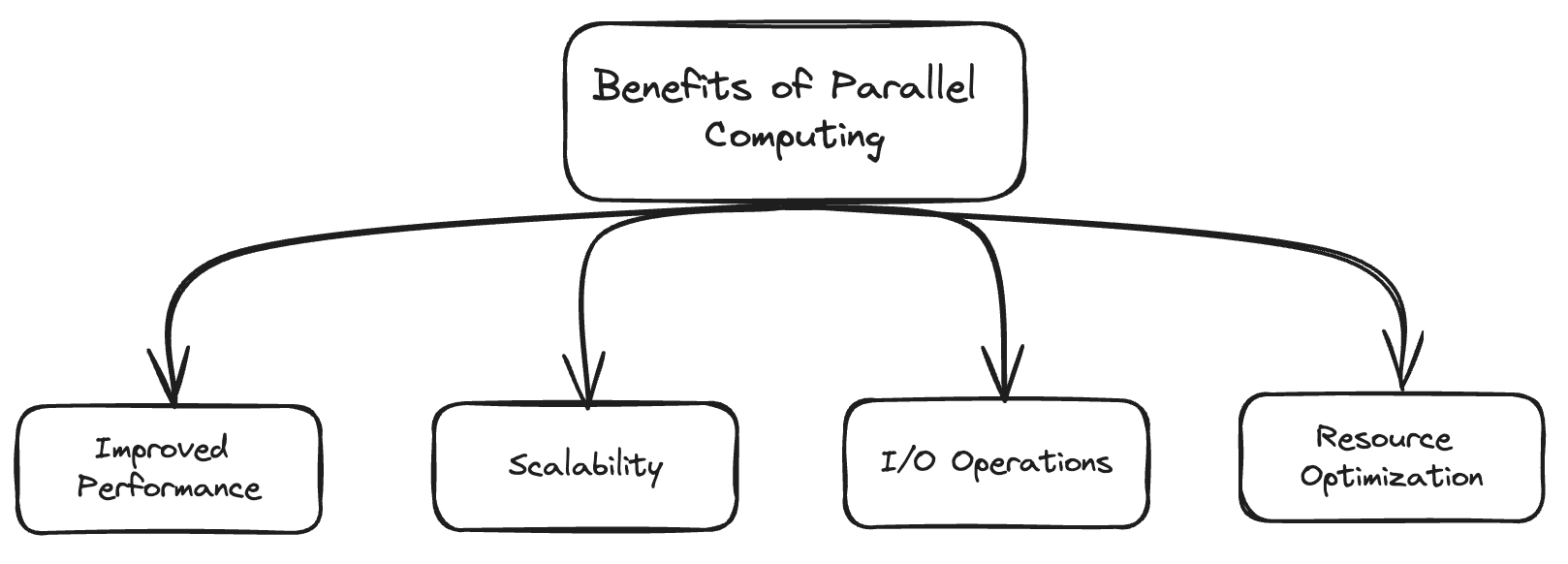
Benefits of Parallel Computing | Image by Author
These are some common reasons for which you require concurrent or parallel executions. Now, move back to the main topics, i.e., Multithreading and Multiprogramming, and discuss their primary differences.
Multithreading is one of the ways to achieve parallelism in a single process and able to execute simultaneous tasks. Multiple threads can be created inside a single process and perform smaller tasks parallel within that process.
The threads present inside a single process share a common memory space, but their stack traces and registers are separate. They are less computationally expensive due to this shared memory.
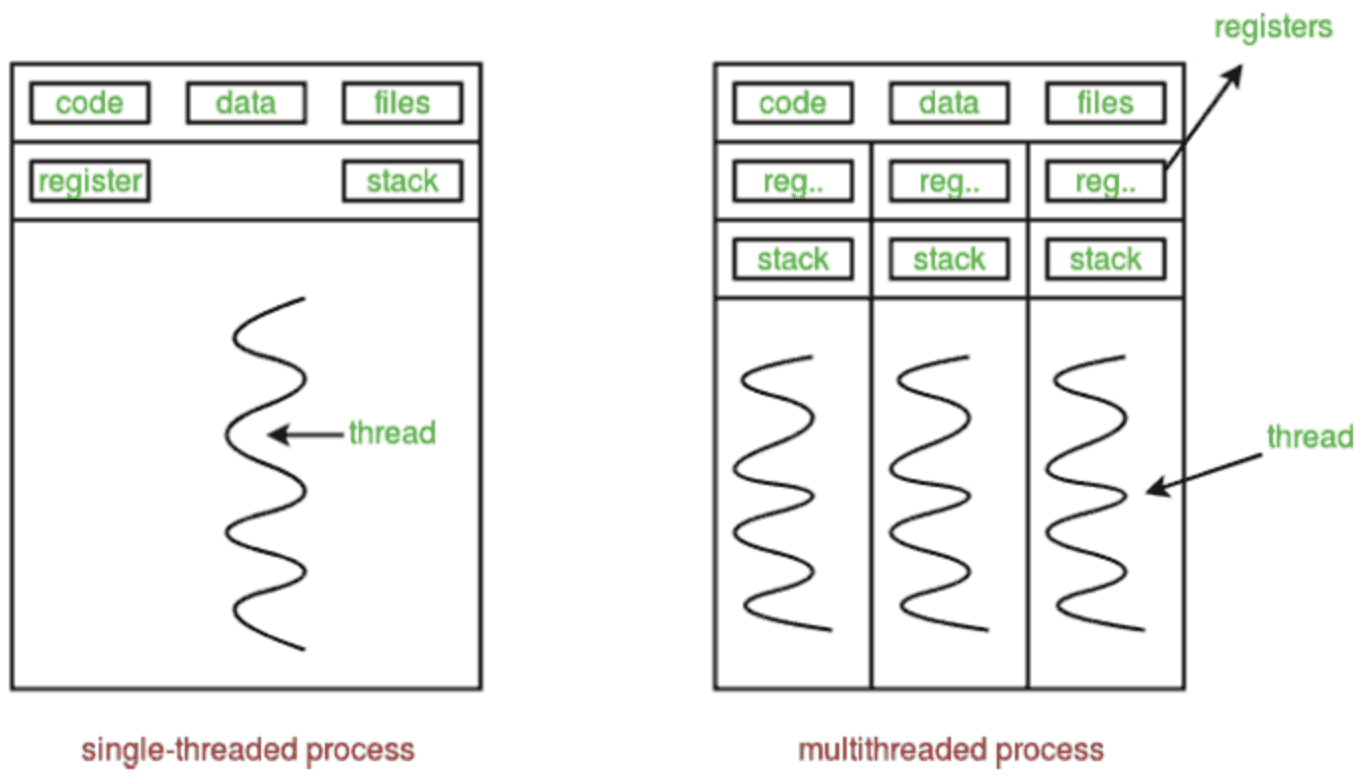
Single Threaded & Multi Threaded Env. | Image by GeeksForGeeks
Multithreading is primarily used in performing I/O operations, i.e., if some part of the program is busy in I/O operations, then the remaining program can be responsive. However, in Python’s implementation, multithreading cannot achieve true parallelism due to Global Interpreter Lock (GIL).
In short, GIL is a mutex lock that allows only one thread at a time to interact with the Python bytecode, i.e., even in the multithreaded mode, only one thread can execute the bytecode at a time.
It is done to maintain thread safety in CPython, but this limits the performance benefits of multithreading. To address this issue, python has a separate multiprocessing library, which we will discuss afterward.
What are Daemon Threads?
The threads which constantly run in the background are called the demon threads. Their main job is to support the main thread or the non-daemon threads. The daemon thread does not block the main thread from execution and even keeps running if it has completed its execution.
In Python, the daemon threads are mainly used as a garbage collector. It will destroy all the useless objects and free the memory by default so that the main thread can be used and executed properly.
Multiprocessing is used to perform the parallel execution of multiple processes. It helps us achieve true parallelism, as we execute separate processes simultaneously, having their own memory space. It uses separate cores of the CPU and is also helpful in performing inter-process communication to exchange data between multiple processes.
Multiprocessing is more computationally expensive as compared to multithreading, as we are not using a shared memory space. Still, it allows us for independent execution and overcomes Global Interpreter Lock’s limitations.
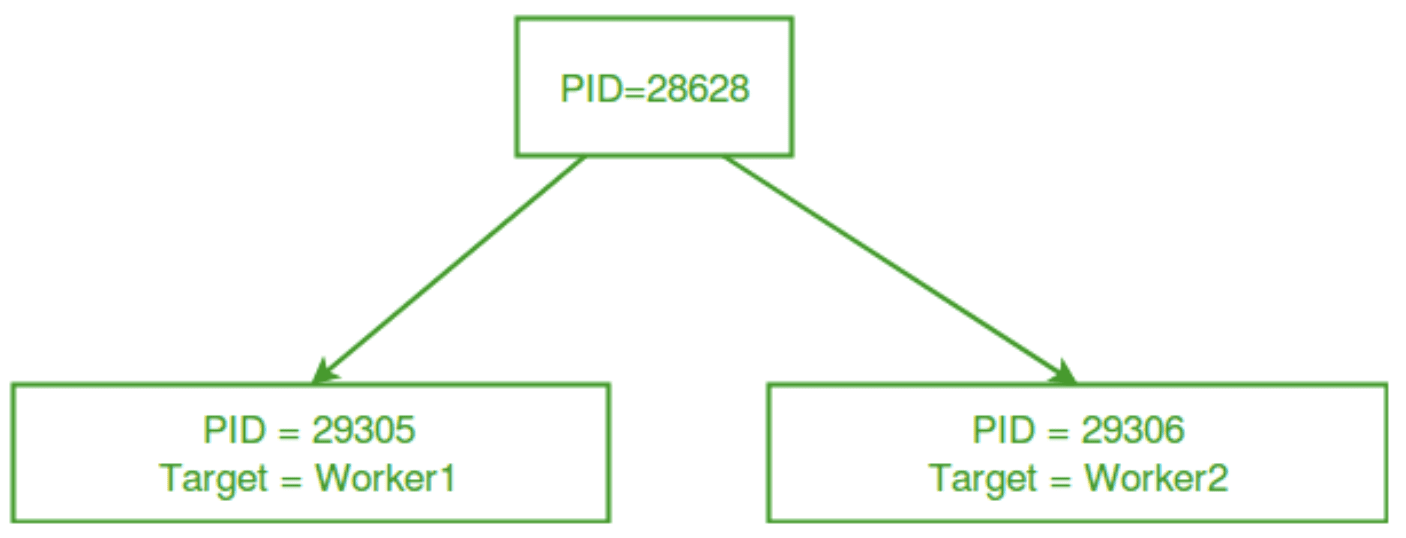
Multiprocessing Environment | Image by GeeksForGeeks
The above figure demonstrates a multi-processing environment in which a main process creates two separate processes and assigns separate work to them.
It’s time to implement a basic example of multithreading using Python. Python has an inbuilt module threading used for the multithreading implementation.
- Importing Libraries:
import threading
import os
- Function to Calculate the Squares:
This is a simple function used to find the square of numbers. A list of numbers is given as input, and it outputs the square of each number of the list along with the name of the thread used and the process ID associated with that thread.
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | Thread Name {threading.current_thread().name} | PID of the process {os.getpid()}"
)
- Main Function:
We have a list of numbers and we will divide that list equally and name them as fisrt_half and second_half respectively. Now we will assign two separate threads t1 and t2 to these lists.
Thread function creates a new thread, which takes a function with a list of arguments to that function. You can also assign a separate name to a thread.
.start() function will start executing these threads and .join() function will block the execution of the main thread until the given thread is not executed completely.
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
t1 = threading.Thread(target=calculate_squares, name="t1", args=(first_half,))
t2 = threading.Thread(target=calculate_squares, name="t2", args=(second_half,))
t1.start()
t2.start()
t1.join()
t2.join()
Output:
Square of the number 1 is 1 | Thread Name t1 | PID of the process 345
Square of the number 2 is 4 | Thread Name t1 | PID of the process 345
Square of the number 5 is 25 | Thread Name t2 | PID of the process 345
Square of the number 3 is 9 | Thread Name t1 | PID of the process 345
Square of the number 6 is 36 | Thread Name t2 | PID of the process 345
Square of the number 4 is 16 | Thread Name t1 | PID of the process 345
Square of the number 7 is 49 | Thread Name t2 | PID of the process 345
Square of the number 8 is 64 | Thread Name t2 | PID of the process 345
Note: All the threads created above are non-daemon threads. To create a daemon thread, you need to write
t1.setDaemon(True)to make the threadt1a daemon thread.
Now, we will understand the output generated by the above code. We can observe that the process ID (i.e., PID) will remain the same for both threads, which means that these two threads are part of the same process.
You can also observe that the output is not generated sequentially. In the first line, you will see the output generated by thread1, then in the 3rd line, the output generated by thread2, then again by thread1 in the fourth line. This clearly signifies that these threads work together concurrently.
Concurrency doesn’t mean these two threads are executed parallelly, as only one thread is executed at a time. It doesn’t reduce the execution time. It takes the same time as sequential execution. CPU starts executing a thread but leaves it midway and moves to another thread, and after some time, comes back to the main thread and starts its execution from the same point it left last time.
I hope you have a basic understanding of multithreading with its implementation and its limitations. Now, it’s time to learn about multiprocessing implementation and how we can overcome those limitations.
We will follow the same example, but instead of creating two separate threads, we will create two independent processes and discuss the observations.
- Importing Libraries:
from multiprocessing import Process
import os
We will use the multiprocessing module to create independent processes.
- Function to Calculate the Squares:
That function will remain the same. We have just removed the print statement of threading information.
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | PID of the process {os.getpid()}"
)
- Main Function:
There are a few modifications in the main function. We have just created a separate process instead of a thread.
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
p1 = Process(target=calculate_squares, args=(first_half,))
p2 = Process(target=calculate_squares, args=(second_half,))
p1.start()
p2.start()
p1.join()
p2.join()
Output:
Square of the number 1 is 1 | PID of the process 1125
Square of the number 2 is 4 | PID of the process 1125
Square of the number 3 is 9 | PID of the process 1125
Square of the number 4 is 16 | PID of the process 1125
Square of the number 5 is 25 | PID of the process 1126
Square of the number 6 is 36 | PID of the process 1126
Square of the number 7 is 49 | PID of the process 1126
Square of the number 8 is 64 | PID of the process 1126
We have observed that a separate process executes each list. Both have different process IDs. To check whether our processes have been executed parallelly, we need to create a separate environment, which we will discuss below.
Calculating Runtime With and Without Multiprocessing
To check whether we get a true parallelism, we will calculate the algorithm’s runtime with and without multiprocessing.
For this, we will require an extensive list of integers that contain more than 10^6 integers. We can generate a list using random library. We will use the time module of Python to calculate the runtime. Below is the implementation for this. The code is self-explanatory, although you can always look at the code comments.
from multiprocessing import Process
import os
import time
import random
def calculate_squares(numbers):
for num in numbers:
square = num * num
if __name__ == "__main__":
numbers = [
random.randrange(1, 50, 1) for i in range(10000000)
] # Creating a random list of integers having size 10^7.
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
# ----------------- Creating Single Process Environment ------------------------#
start_time = time.time() # Start time without multiprocessing
p1 = Process(
target=calculate_squares, args=(numbers,)
) # Single process P1 is executing all list
p1.start()
p1.join()
end_time = time.time() # End time without multiprocessing
print(f"Execution Time Without Multiprocessing: {(end_time-start_time)*10**3}ms")
# ----------------- Creating Multi Process Environment ------------------------#
start_time = time.time() # Start time with multiprocessing
p2 = Process(target=calculate_squares, args=(first_half,))
p3 = Process(target=calculate_squares, args=(second_half,))
p2.start()
p3.start()
p2.join()
p3.join()
end_time = time.time() # End time with multiprocessing
print(f"Execution Time With Multiprocessing: {(end_time-start_time)*10**3}ms")
Output:
Execution Time Without Multiprocessing: 619.8039054870605ms
Execution Time With Multiprocessing: 321.70287895202637ms
You can observe that the time with multiprocessing is almost half as compared to without multiprocessing. This shows that these two processes are executed simultaneously at a time and show a behavior of true parallelism.
You can also read this article Sequential vs Concurrent vs Parallelism from Medium, which will help you to understand the basic difference between these Sequential, Concurrent and Parallel processes.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.