There’s a burgeoning interest in technologies that can transform textual descriptions into videos. This area, blending creativity with cutting-edge tech, is not just about generating static images from text but about animating these images to create coherent, lifelike videos. The quest for producing high-fidelity, aesthetically pleasing videos that accurately reflect the described scenarios presents a notable challenge. Achieving seamless integration of visual quality with fluid motion is complex, necessitating innovative approaches.
One significant obstacle in AI-generated media is crafting videos that are visually striking and embody smooth motion and consistency. Existing methods have primarily focused on generating static images from text and subsequently animating these images. However, these techniques must be revised to maintain quality and consistency, particularly in smooth motion and high-resolution output.
The researchers from Bytedance Inc. introduced an advanced framework called MagicVideo-V2, which marks a paradigm shift in video generation. This innovative multi-stage framework amalgamates several modules, each critical in transforming a textual description into a high-quality video. MagicVideo-V2 starts with a text-to-image module, which serves as the foundation by creating an initial image that encapsulates the essence of the input text. This image is then processed through a series of modules contributing to the final output.
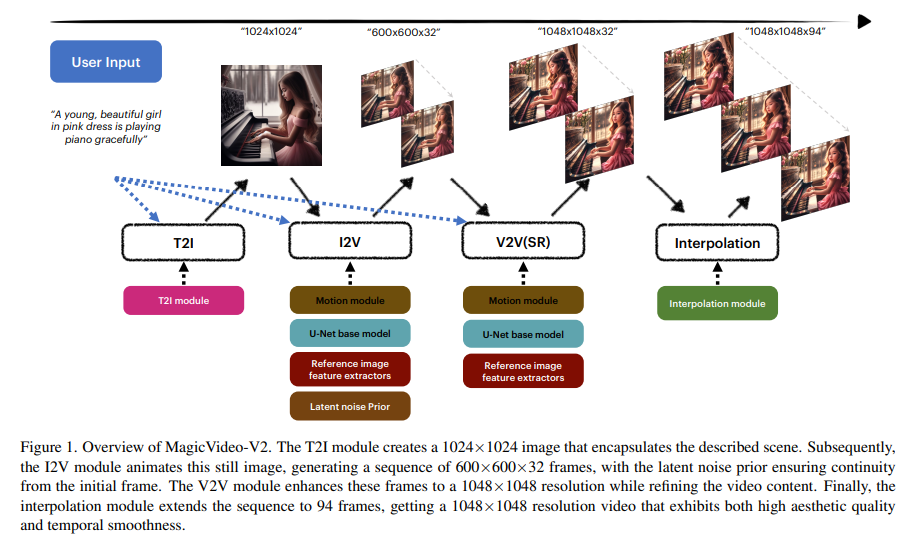
MagicVideo-V2’s methodology is intricate and multifaceted. After the initial image generation, the image-to-video module animates this still image, creating a sequence of frames that form the backbone of the video. This module is pivotal in ensuring the initial frames align with the text’s aesthetic and thematic elements. Following this, the video-to-video module enhances the resolution and details of these frames, providing high-quality visuals. The final piece of the puzzle is the video frame interpolation module, which adds fluidity and smoothness to the motion in the video.
When pitted against other leading text-to-video systems, it demonstrated superior performance in several aspects. In a comparative analysis, human evaluators showed a strong preference for MagicVideo-V2 over its competitors. The evaluation focused on frame quality, motion consistency, and structural accuracy. The results highlighted the technical proficiency of MagicVideo-V2 and its ability to align closely with human perceptions of video quality.

MagicVideo-V2 represents a significant advancement in the realm of AI-driven video generation. It sets a new benchmark in this field by addressing key challenges such as creating high-fidelity, aesthetically pleasing videos with coherent motion. Its multi-stage approach, integrating innovative modules, demonstrates the potential for future advancements in AI and video generation. This research opens up new possibilities for creating dynamic, high-quality content from textual descriptions, showcasing AI’s impressive capabilities in digital media creation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.