A significant challenge in the field of visual question answering (VQA) is the task of Multi-Image Visual Question Answering (MIQA). This involves generating relevant and grounded responses to natural language queries based on a large set of images. Existing Large Multimodal Models (LMMs) excel in single-image visual question answering but face substantial difficulties when queries span extensive image collections. Addressing this challenge is crucial for real-world applications like searching through large photo albums, finding specific information across the internet, or monitoring environmental changes through satellite imagery.
Current methods for visual question answering primarily focus on single-image analysis, which limits their utility for more complex queries involving large image sets. Models like Gemini 1.5-pro and GPT-4V can process multiple images but encounter significant challenges in efficiently retrieving and integrating relevant images from large datasets. These methods are computationally inefficient and exhibit performance degradation as the volume and variability of images increase. They also suffer from positional bias and struggle with integrating visual information across numerous unrelated images, leading to a decline in accuracy and applicability in large-scale tasks.

To address these limitations, researchers from the University of California propose MIRAGE (Multi-Image Retrieval Augmented Generation), a novel framework tailored for MIQA. MIRAGE extends the LLaVA model by integrating several innovative components: a compressive image encoder, a retrieval-based, query-aware relevance filter, and augmented training with targeted synthetic and real MIQA data. These innovations enable MIRAGE to handle larger image contexts efficiently and improve accuracy in answering MIQA tasks. This approach represents a significant contribution to the field, offering up to an 11% accuracy improvement over closed-source models like GPT-4o on the Visual Haystacks (VHs) benchmark, and demonstrating up to 3.4x improvements in efficiency over traditional text-focused multi-stage approaches.
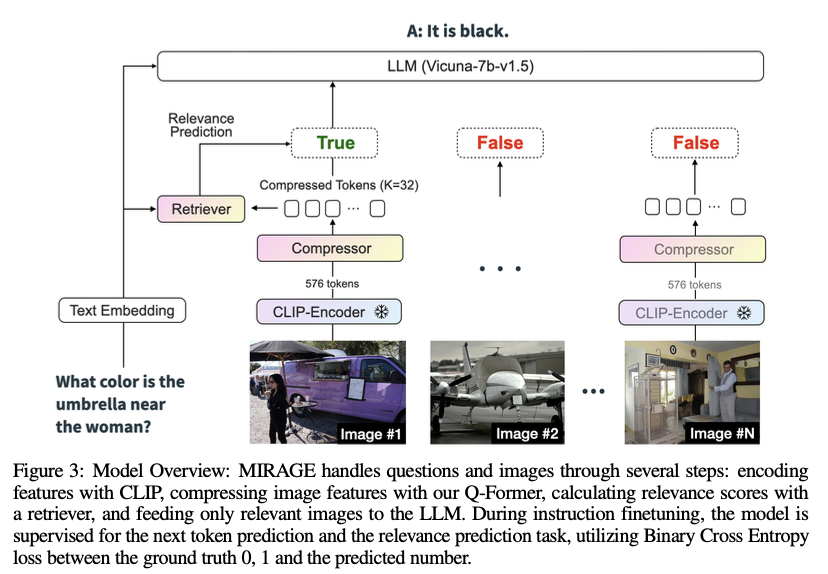
MIRAGE employs a compressive image encoding mechanism using a Q-former to reduce the token intensity per image from 576 to 32 tokens. This allows the model to handle more images within the same context budget. The query-aware relevance filter is a single-layer MLP that predicts the relevance of images to the query, which is then used to select relevant images for detailed analysis. The training process involves both existing MIQA datasets and synthetic data derived from single-image QA datasets, enhancing the model’s robustness and performance across varied MIQA scenarios. The VHs dataset used for benchmarking contains 880 single-needle and 1000 multi-needle question-answer pairs, providing a rigorous evaluation framework for MIQA models.
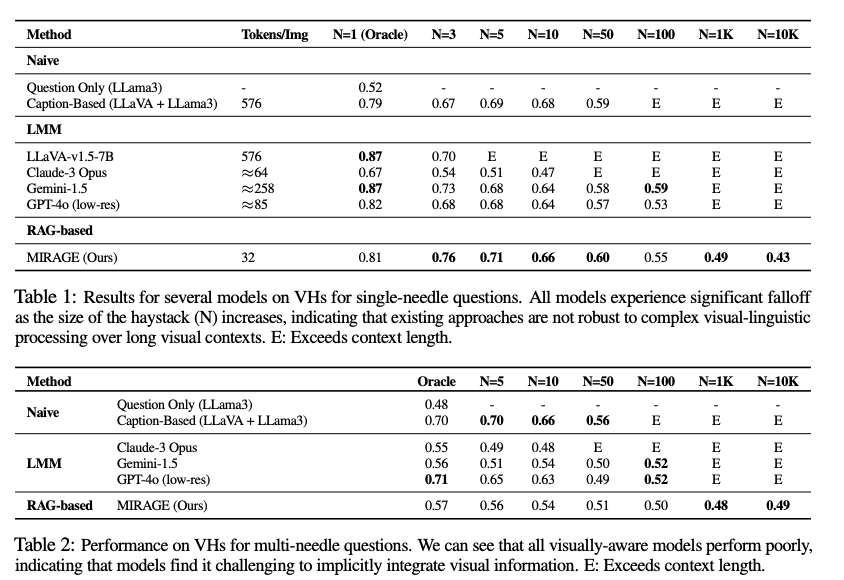
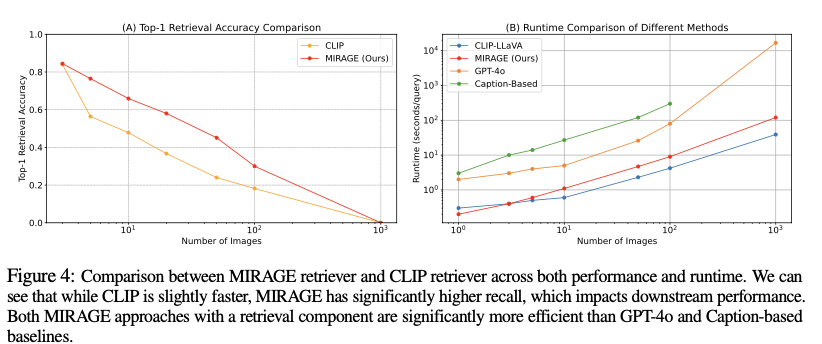
Evaluation results show that MIRAGE significantly outperforms existing models on the Visual Haystacks benchmark, surpassing closed-source models like GPT-4o by up to 11% in accuracy for single-needle questions and demonstrating notable improvements in efficiency. MIRAGE maintains higher performance levels as the size of the image sets increases, showcasing its robustness in handling extensive visual contexts. It achieved substantial improvements in both accuracy and processing efficiency compared to traditional text-focused multi-stage approaches.
In conclusion, the researchers present a significant advancement in MIQA with the MIRAGE framework. The critical challenge of efficiently retrieving and integrating relevant images from large datasets to answer complex visual queries is addressed. MIRAGE’s innovative components and robust training methods lead to superior performance and efficiency compared to existing models, paving the way for more effective AI applications in real-world scenarios involving extensive visual data.
Check out the Paper, Project, GitHub, and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.