
 | by Beatriz Stollnitz | Sep, 2023")
Learn how to add your own proprietary data to a pre-trained LLM using a prompt-based technique called Retrieval-Augmented Generation
Introduction
Large Language Models (LLMs) know a lot about the world, but they don’t know everything. Since training these models takes a long time, the data they were last trained on can be pretty old. And although LLMs know about general-purpose facts available on the internet, they don’t know about your proprietary data, which is often the data you need in your AI-based application. So it’s no surprise that extending LLMs with new data has been a considerable area of focus lately, both in academia and in the industry.
Before this new era of large language models, we would often extend models with new data by simply fine-tuning them. But now that our models are much larger and have been trained with much more data, fine-tuning is only appropriate for a few scenarios. Fine-tuning performs particularly well when we want to make our LLM communicate in a different style or tone. One great example of fine-tuning is OpenAI’s adaptation of their older completion-style GPT-3.5 models into their newer chat-style GPT-3.5-turbo (ChatGPT) models. Their completion-style models, if given the input “Can you tell me about cold-weather tents”, might reply by extending the prompt: “and any other cold-weather camping equipment?” On the other hand, their chat-style models might reply instead with an answer: “Certainly! They’re designed to withstand low temperatures, high winds, and snow by…” In this case, OpenAI’s focus was not to update the information the model had access to, but rather to change the way it converses with users. And for that, fine-tuning does wonders!
However, fine-tuning doesn’t perform as well for adding new data to large models, which I have found to be a much more common business scenario. In addition, fine-tuning LLMs requires a large amount of high quality data, a big budget to spend on compute resources, and a lot of time — all of which are scarce resources for most users.
In this post, we’ll cover an alternative technique called “Retrieval-Augmented Generation” (RAG). This approach is based on prompting and it was introduced by Facebook AI Research (FAIR) and collaborators in 2021. The RAG concept is powerful enough that it’s used by Bing search and other high-traffic sites to incorporate current data into their models, and yet simple enough that I can explain it to you in depth in this blog post. It’s also effective when you don’t have a large amount of new data, a big budget, or a lot of time.
You can find three code implementations for a simple RAG scenario in the GitHub repo associated with this blog post: one that uses the OpenAI APIs directly, another that uses the open-source LangChain API, and a third implementation that uses the open-source Semantic Kernel API. I will show and explain the code for the first scenario in this blog post, and encourage you to browse the others on your own time.
But before we dive into the code, let’s learn the fundamental concepts of RAG.
An overview of RAG
Retrieval-Augmented Generation can vary in its implementation, but at a conceptual level, using RAG in an AI-based application involves the following steps:
- The user inputs a question.
- The system searches for relevant documents that might answer the question. These documents often consist of proprietary data, and are stored in some kind of document index.
- The system creates an LLM prompt that combines the user input, the related documents, and instructions for the LLM to answer the user’s question using the documents provided.
- The system sends the prompt to an LLM.
- The LLM returns an answer to the user’s question, grounded by the context we provided. This is the output of our system.
Here’s a diagram of this general idea:

I’ve given you a colloquial meaning for RAG, but it’s somewhat lacking in implementation details. Let’s take a closer look at the paper that introduced this idea to start grasping the specifics.
The RAG research paper
The term RAG was first introduced by FAIR and academic collaborators in 2021, in their paper titled Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. The ideas presented by the authors had a tremendous impact in the industry solutions we use today, so they’re worth getting familiar with.
Here’s an overview of the architecture presented in the paper:
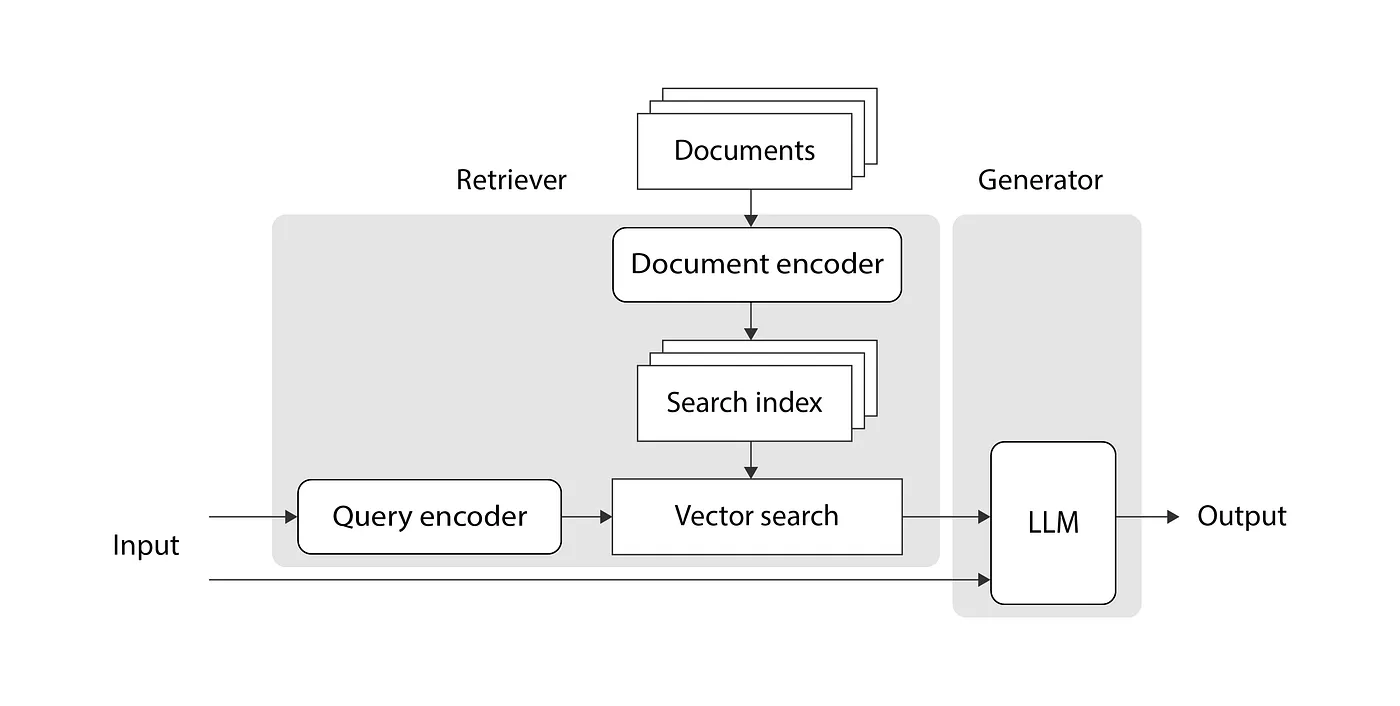
We’ll look at each piece of this architecture in depth throughout this post. At a high level, the proposed structure is composed of two components: a retriever and a generator. The retriever component transforms the input text into a sequence of floating point numbers (a vector) using the query encoder, transforms each document in the same way using the document encoder, and stores the document encodings in a search index. It then searches the search index for document vectors that are related to the input vector, converts the document vectors back into text, and returns their text as output. The generator then takes the user’s input text and matched documents, combines them into a prompt, and asks an LLM for a reply to the user’s input given the information in the documents. The output of that LLM is the output of the system.
You may have noticed that the query encoder, document encoder, and LLM are all represented similarly in the image above — that’s because they’re all implemented using transformers. Traditional transformers are composed of two parts: an encoder and a decoder. The encoder is responsible for transforming the input text into a vector (or sequence of vectors) that roughly captures the meaning of the words; and the decoder is responsible for generating new text based on the input text. In the paper’s architecture, the query encoder and document encoder are implemented using encoder-only transformers because they just need to transform pieces of text into vectors of numbers. The LLM in the generator is implemented using a traditional encoder-decoder transformer.
How is this architecture trained? The paper proposes using pre-trained transformers, and jointly fine-tuning the query encoder and generator LLM only. This fine-tuning is done using pairs of user inputs and the corresponding outputs expected from the LLM. The document encoder is not fine-tuned because that would be costly and the authors found that it’s not necessary for good performance.
The paper proposes two approaches for the implementation of this architecture:
- RAG-sequence — We retrieve k documents, and use them to generate all the output tokens that answer a user query.
- RAG-token— We retrieve k documents, use them to generate the next token, then retrieve k more documents, use them to generate the next token, and so on. This means that we could end up retrieving several different sets of documents in the generation of a single answer to a user’s query.
You now have a good high-level understanding of the architecture in the RAG paper. This pattern is very common in the industry; however, it turns out that not every detail in the paper is implemented exactly as proposed.
RAG as used in the industry
In practice, the RAG implementations that are common in the industry have been adapted from the paper in the following ways:
- Of the two approaches proposed in the paper, the RAG-sequence implementation is pretty much always used in the industry. It’s cheaper and simpler to run than the alternative, and it produces great results.
- We don’t generally fine-tune any of the transformers. The pre-trained LLMs available to us these days are good enough to use as is, and too costly to fine-tune ourselves.
In addition, the method for searching documents isn’t always done exactly as proposed by the paper. Search is commonly done with the help of a search service, such as FAISS or Azure Cognitive Search, and these services support different search techniques that pair well with RAG. A search service is generally composed of the following two steps of execution:
- Retrieval: This step compares the user’s query with the documents in the search index, and retrieves the most relevant documents. There are three common retrieval techniques: keyword search, vector search, and hybrid search.
- Ranking: This is an optional step that follows retrieval. It takes the list of documents that were found relevant by retrieval and improves on the order in which they’re ranked.
Let’s learn about each of these in more detail, starting with the three types of retrieval.
Keyword search
The simplest way to find documents that are related to a user query is to do a “keyword search” (also known as “full-text search”). Keyword search uses the exact terms in the user input text to search an index for documents with matching text. The matching is done based on text only, with no vectors involved. Even though this technique has been around for a while, it’s still relevant today. This type of search is very useful when you’re searching for user IDs, product codes, addresses, and any other data that requires high precision matches. Here’s a high-level diagram of this implementation:

In this scenario, our search service keeps an inverted index that maps from words to documents that use those words. The user’s text input is parsed to extract search terms, and analyzed to find standard forms of those terms. The inverted index is then scanned for the search terms, each match is scored, and the most relevant matching documents are returned from the search service.
Vector search
“Vector search” (also known as “dense retrieval”) differs from keyword search in the sense that it can find matches when no search terms are present in the documents, but the general ideas are similar. For example, suppose you’re building a chatbot to support a property rental site. If the user asks, “Do you have recommendations for a spacious apartment close to the sea?” and the document for a particular property contains the text “4000 sq ft home with ocean view,” keyword search won’t identify that as a match, but vector search will. Vector search works best when we’re searching unstructured text for general ideas, rather than precise keywords.
Here’s a high-level overview of RAG with vector search:

As you can see in the diagram, vector search as used in the industry is pretty much the same as the RAG paper proposal. Except that in this case we don’t fine-tune the transformers.
We typically use a pre-trained embedding model such as OpenAI’s text-embedding-ada-002 to encode the query and documents, and a pre-trained LLM such as OpenAI’s gpt-35-turbo (ChatGPT) to produce the final output. The embedding model is used to translate the input text and each of our documents into a corresponding “embedding.” What’s an embedding? It’s a vector of floating-point numbers that roughly captures the general idea of the text it encodes. If two pieces of text are related, then we can assume that the corresponding embedding vectors are similar.
How can we determine if two vectors are similar? Let’s look at an example to answer that question. We’ll assume that we used our embedding model to compute the following embedding vectors:
- a = (0, 1) represents “Do you have recommendations for a spacious apartment close to the sea?”
- b = (0.12, 0.99) represents “4000 sq ft home with ocean view”
- c = (0.96, 0.26) represents “I want a donut”
We can plot these in a graph:

Looking at the image, you can intuitively tell that the vector that’s most simlar to a is b (rather than c). Progammatically speaking, there are three common methods for calculating vector similarity: dot product, cosine similarity, and Euclidean distance. Let’s calculate similarities using these methods, and see if we can validate our intuition.
The dot product method, as you’d expect, simply calculates the dot product (also known as the inner product) between two vectors. The larger the result, the more similar the vectors are:

The dot product between a and b is larger than the dot product between a and c, which confirms our intuition that a and b are more similar. Keep in mind that the dot product is strongly influenced by the lengths of the vectors, and really only measures similarity if the vectors all have the same length. OpenAI embeddings always have length one, and to be consistent with OpenAI our sample embeddings also have length one.
Cosine similarity calculates the cosine of the angle between two vectors, and the larger the cosine, the more similar the vectors are. The formula to calculate it starts out similar to the dot product, but the vectors are then divided by the product of their lengths. As a result of this extra normalization step, cosine similarity effectively measures the similarity between two vectors by accounting for their directions while ignoring their lengths.

Because our vectors have length one, dot product and cosine similarity produce exactly the same results, as you can see in the calculations above.
Euclidean distance measures distance between two vectors, in the usual sense. The smaller the distance between two vectors, the more similar they are. Unlike cosine similarity, Euclidean distance takes into account the length and direction of the vectors.

As you can see, the distance between a and b is smaller than a and c, which means that a and b are most similar.
Our sample uses 2D vectors so that we can get some visual intuition, but it’s common for embedding vectors to have many more dimensions. For example, the text-embedding-ada-002 model from OpenAI generates vectors with 1536 dimensions. Keep in mind that the number of dimensions used for embeddings doesn’t depend on the length of the input text, so a short query and a long document will both result in an embedding vector with the same number of dimensions.
Most search services available today support the three similarity methods we discussed, and allow you to choose the method you want to use. Which similarity technique should you choose?
- If your embeddings have different lengths and you want to take those lengths into account, then Euclidean distance is the best choice, because it considers both length and direction.
- If your embeddings have all been normalized to unit length, then all three solutions will give you the same ranking, as you saw. However, dot product is slightly cheaper to compute. If an app or service you’re working with knows it’s dealing with unit length vectors, then most likely its cosine similarity implementation has been optimized to use the same calculations as dot product. So most likely cosine similarity is as cheap to compute as dot product in this case.
In order to find the top document vectors for a given input vector, our search service could simply use brute force to calculate the similarity between the input vector and each document vector, and then select the top matches. However, this simple algorithm wouldn’t scale to large enterprise applications with lots of document vectors. Therefore search services generally use some type of Approximate Nearest Neighbor (ANN) algorithm, which use clever optimizations to give approximate results in much less time. One popular implementation of ANN is the Hierarchical Navigable Small World (HNSW) algorithm.
Hybrid search
Hybrid search consists of the simultaneous use of keyword and vector search. For example, let’s consider a scenario where you have a customer ID and a text input query, and you want to do a search that captures both the high-precision of the customer ID and the general meaning of the user text. This is the perfect scenario for hybrid search. Hybrid search performs the two types of search separately, and then it combines the outputs using an algorithm that selects the best results of each technique. This method is used often in the industry, especially in more complex applications.
Semantic ranking
Semantic ranking (also known as “rerank”) is an optional step that follows the retrieval of documents. The retrieval step does its best to rank the returned documents based on how relevant they are to the user’s query, but the semantic ranking step can often improve on that result. It takes a subset of the documents returned by the retrieval, computes higher quality relevance scores using an LLM that is trained just for that task, and reranks the documents based on those scores.

In the image above I show semantic ranking combined with vector search, but you could easily combine it with keyword search instead. I decided to show semantic ranking with vector search in the diagram because that’s the solution I’ve implemented in the code for this post, which we’ll look at next.
A simple implementation of RAG
In this section, we’ll take a look at code that adds our own custom data to ChatGPT, using RAG and Azure Cognitive Search. The code I’ll show here uses OpenAI APIs to interact with ChatGPT directly, but in the same GitHub project, you’ll find two other similar implementations: one that uses LangChain and another that uses Semantic Kernel. These are two popular open-source frameworks that help developers build applications with LLMs.
The goal for this project is to create a chatbot that our users can leverage to get more information about the products our company sells. The data we’ll use consists of several markdown files containing details about our products.
Let’s start by looking at init_search_1.py:
"""
Initializes an Azure Cognitive Search index with our custom data, using vector search
and semantic ranking.To run this code, you must already have a "Cognitive Search" and an "OpenAI"
resource created in Azure.
"""
import os
import openai
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (
HnswParameters,
HnswVectorSearchAlgorithmConfiguration,
PrioritizedFields,
SearchableField,
SearchField,
SearchFieldDataType,
SearchIndex,
SemanticConfiguration,
SemanticField,
SemanticSettings,
SimpleField,
VectorSearch,
)
from dotenv import load_dotenv
from langchain.document_loaders import DirectoryLoader, UnstructuredMarkdownLoader
from langchain.text_splitter import Language, RecursiveCharacterTextSplitter
# Config for Azure Search.
AZURE_SEARCH_ENDPOINT = os.getenv("AZURE_SEARCH_ENDPOINT")
AZURE_SEARCH_KEY = os.getenv("AZURE_SEARCH_KEY")
AZURE_SEARCH_INDEX_NAME = "products-index-1"
# Config for Azure OpenAI.
AZURE_OPENAI_API_TYPE = "azure"
AZURE_OPENAI_API_BASE = os.getenv("AZURE_OPENAI_API_BASE")
AZURE_OPENAI_API_VERSION = "2023-03-15-preview"
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_EMBEDDING_DEPLOYMENT = os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT")
DATA_DIR = "data/"
def load_and_split_documents() -> list[dict]:
"""
Loads our documents from disc and split them into chunks.
Returns a list of dictionaries.
"""
# Load our data.
loader = DirectoryLoader(
DATA_DIR, loader_cls=UnstructuredMarkdownLoader, show_progress=True
)
docs = loader.load()
# Split our documents.
splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN, chunk_size=6000, chunk_overlap=100
)
split_docs = splitter.split_documents(docs)
# Convert our LangChain Documents to a list of dictionaries.
final_docs = []
for i, doc in enumerate(split_docs):
doc_dict = {
"id": str(i),
"content": doc.page_content,
"sourcefile": os.path.basename(doc.metadata["source"]),
}
final_docs.append(doc_dict)
return final_docs
def get_index(name: str) -> SearchIndex:
"""
Returns an Azure Cognitive Search index with the given name.
"""
# The fields we want to index. The "embedding" field is a vector field that will
# be used for vector search.
fields = [
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SimpleField(name="sourcefile", type=SearchFieldDataType.String),
SearchableField(name="content", type=SearchFieldDataType.String),
SearchField(
name="embedding",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
# Size of the vector created by the text-embedding-ada-002 model.
vector_search_dimensions=1536,
vector_search_configuration="default",
),
]
# The "content" field should be prioritized for semantic ranking.
semantic_settings = SemanticSettings(
configurations=[
SemanticConfiguration(
name="default",
prioritized_fields=PrioritizedFields(
title_field=None,
prioritized_content_fields=[SemanticField(field_name="content")],
),
)
]
)
# For vector search, we want to use the HNSW (Hierarchical Navigable Small World)
# algorithm (a type of approximate nearest neighbor search algorithm) with cosine
# distance.
vector_search = VectorSearch(
algorithm_configurations=[
HnswVectorSearchAlgorithmConfiguration(
name="default",
kind="hnsw",
parameters=HnswParameters(metric="cosine"),
)
]
)
# Create the search index.
index = SearchIndex(
name=name,
fields=fields,
semantic_settings=semantic_settings,
vector_search=vector_search,
)
return index
def initialize(search_index_client: SearchIndexClient):
"""
Initializes an Azure Cognitive Search index with our custom data, using vector
search.
"""
# Load our data.
docs = load_and_split_documents()
for doc in docs:
doc["embedding"] = openai.Embedding.create(
engine=AZURE_OPENAI_EMBEDDING_DEPLOYMENT, input=doc["content"]
)["data"][0]["embedding"]
# Create an Azure Cognitive Search index.
index = get_index(AZURE_SEARCH_INDEX_NAME)
search_index_client.create_or_update_index(index)
# Upload our data to the index.
search_client = SearchClient(
endpoint=AZURE_SEARCH_ENDPOINT,
index_name=AZURE_SEARCH_INDEX_NAME,
credential=AzureKeyCredential(AZURE_SEARCH_KEY),
)
search_client.upload_documents(docs)
def delete(search_index_client: SearchIndexClient):
"""
Deletes the Azure Cognitive Search index.
"""
search_index_client.delete_index(AZURE_SEARCH_INDEX_NAME)
def main():
load_dotenv()
openai.api_type = AZURE_OPENAI_API_TYPE
openai.api_base = AZURE_OPENAI_API_BASE
openai.api_version = AZURE_OPENAI_API_VERSION
openai.api_key = AZURE_OPENAI_API_KEY
search_index_client = SearchIndexClient(
AZURE_SEARCH_ENDPOINT, AzureKeyCredential(AZURE_SEARCH_KEY)
)
initialize(search_index_client)
# delete(search_index_client)
if __name__ == "__main__":
main()
Our first task is to load the markdown data files and split them into chunks of 6000 characters, with 100 characters of overlap between chunks. Each of these data chunks will later be encoded by a single embedding and added to the search index. If our files are small enough, we don’t need to break them into chunks, and can encode each file as is. But if they’re big, it’s better to break them up, because our embedding has a fixed size and won’t be able to capture all the information as well. We add some overlap to the chunks so that we don’t lose ideas that cross chunk boundaries.
Next we create a list that contains a dictionary per chunk, specifying the text of the chunk, a unique ID, and the name of the source file. We then calculate the embedding for each chunk using OpenAI’s text-embedding-ada-002 model, and insert that into the chunk’s dictionary as well. This list of dictionaries contains all the information needed to populate a search index.
Next, we create the search index using the Azure Cognitive Search API. We configure the fields that will be created in the index, taking care to specify that the field with the embedding needs to support vector search. We configure our vector search by saying that the embedding size is 1536 (which is always the case for the OpenAI model we’re using), that we want to use the cosine method for vector similarity comparison (as recommended by OpenAI), and that we want to use the Hierarchical Navigable Small World (HNSW) algorithm to speed up the comparison search. We also specify that we want to enable semantic ranking for our context text field. We give our index a name, and save it.
Last, we upload our data to the search index we just created. You can confirm that all the chunks have been added to the index by going to the Azure portal, clicking on your Cognitive Search resource, then on the name of your resource, and then on “Indexes.” You should see your index listed on the right side, together with the document count, which is the number of chunks that were uploaded to the index (I have 45 chunks in my index). If you click on the index name, you can see the data that was uploaded to it by clicking the “Search” button within “Search Explorer”:

If you look at the equivalent init_search files in the LangChain and Semantic Kernel folders, you’ll see that they contain much less code. Using the Azure Cognitive Search APIs directly gives you more control over the configuration of the index, and using a library as an intermediary hides away a lot of the complexity. The best option really depends on what you’re looking for.
Now that we’ve established our search index, we’ll see how the index can be used in a chatbot. Let’s look at the main_1.py file, which is our main executable file for the chatbot:
"""
Entry point for the chatbot.
"""
from chatbot_1 import Chatbotdef main():
chatbot = Chatbot()
chatbot.ask("I need a large backpack. Which one do you recommend?")
chatbot.ask("How much does it cost?")
chatbot.ask("And how much for a donut?")
if __name__ == "__main__":
main()
The main function pretends to be a user, asking the chatbot a sequence of questions. For each question, the code simply invokes the ask function of the chatbot. The equivalent files in the LangChain and Semantic Kernel versions look essentially the same.
Last, let’s look at the chatbot_1.py file, which contains the code for a chatbot that remembers the conversation history and knows how to implement RAG:
"""
Chatbot with context and memory.
"""
import osimport openai
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.search.documents.models import Vector
from dotenv import load_dotenv
# Config for Azure Search.
AZURE_SEARCH_ENDPOINT = os.getenv("AZURE_SEARCH_ENDPOINT")
AZURE_SEARCH_KEY = os.getenv("AZURE_SEARCH_KEY")
AZURE_SEARCH_INDEX_NAME = "products-index-1"
# Config for Azure OpenAI.
AZURE_OPENAI_API_TYPE = "azure"
AZURE_OPENAI_API_BASE = os.getenv("AZURE_OPENAI_API_BASE")
AZURE_OPENAI_API_VERSION = "2023-03-15-preview"
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
AZURE_OPENAI_CHATGPT_DEPLOYMENT = os.getenv("AZURE_OPENAI_CHATGPT_DEPLOYMENT")
AZURE_OPENAI_EMBEDDING_DEPLOYMENT = os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT")
# Chat roles
SYSTEM = "system"
USER = "user"
ASSISTANT = "assistant"
class Chatbot:
"""Chat with an LLM using RAG. Keeps chat history in memory."""
chat_history = []
def __init__(self):
load_dotenv()
openai.api_type = AZURE_OPENAI_API_TYPE
openai.api_base = AZURE_OPENAI_API_BASE
openai.api_version = AZURE_OPENAI_API_VERSION
openai.api_key = AZURE_OPENAI_API_KEY
def _summarize_user_intent(self, query: str) -> str:
"""
Creates a user message containing the user intent, by summarizing the chat
history and user query.
"""
chat_history_str = ""
for entry in self.chat_history:
chat_history_str += f"{entry['role']}: {entry['content']}\n"
messages = [
{
"role": SYSTEM,
"content": (
"You're an AI assistant reading the transcript of a conversation "
"between a user and an assistant. Given the chat history and "
"user's query, infer user real intent."
f"Chat history: ```{chat_history_str}```\n"
f"User's query: ```{query}```\n"
),
}
]
chat_intent_completion = openai.ChatCompletion.create(
deployment_id=AZURE_OPENAI_CHATGPT_DEPLOYMENT,
messages=messages,
temperature=0.7,
max_tokens=1024,
n=1,
)
user_intent = chat_intent_completion.choices[0].message.content
return user_intent
def _get_context(self, user_intent: str) -> list[str]:
"""
Gets the relevant documents from Azure Cognitive Search.
"""
query_vector = Vector(
value=openai.Embedding.create(
engine=AZURE_OPENAI_EMBEDDING_DEPLOYMENT, input=user_intent
)["data"][0]["embedding"],
fields="embedding",
)
search_client = SearchClient(
endpoint=AZURE_SEARCH_ENDPOINT,
index_name=AZURE_SEARCH_INDEX_NAME,
credential=AzureKeyCredential(AZURE_SEARCH_KEY),
)
docs = search_client.search(search_text="", vectors=[query_vector], top=1)
context_list = [doc["content"] for doc in docs]
return context_list
def _rag(self, context_list: list[str], query: str) -> str:
"""
Asks the LLM to answer the user's query with the context provided.
"""
user_message = {"role": USER, "content": query}
self.chat_history.append(user_message)
context = "\n\n".join(context_list)
messages = [
{
"role": SYSTEM,
"content": (
"You're a helpful assistant.\n"
"Please answer the user's question using only information you can "
"find in the context.\n"
"If the user's question is unrelated to the information in the "
"context, say you don't know.\n"
f"Context: ```{context}```\n"
),
}
]
messages = messages + self.chat_history
chat_completion = openai.ChatCompletion.create(
deployment_id=AZURE_OPENAI_CHATGPT_DEPLOYMENT,
messages=messages,
temperature=0.7,
max_tokens=1024,
n=1,
)
response = chat_completion.choices[0].message.content
assistant_message = {"role": ASSISTANT, "content": response}
self.chat_history.append(assistant_message)
return response
def ask(self, query: str) -> str:
"""
Queries an LLM using RAG.
"""
user_intent = self._summarize_user_intent(query)
context_list = self._get_context(user_intent)
response = self._rag(context_list, query)
print(
"*****\n"
f"QUESTION:\n{query}\n"
f"USER INTENT:\n{user_intent}\n"
f"RESPONSE:\n{response}\n"
"*****\n"
)
return response
Our chatbot keeps a chat_history list of questions and answers in memory, so that it can make sense of questions in the context of the entire conversation. The Chatbot class has a single public ask function, which contains the following steps:
- The _summarize_user_intent function uses an LLM to rephrase the user’s question while taking into account any previous chat history. Why do we need this step? Suppose the user asks a question that doesn’t quite make sense on its own, but makes sense when seen in the context of the chat history; for example, if a question mentions “it” in reference to a previous topic. If we search our index for documents related to the user’s question on its own, we probably won’t get good results. But if we rephrase the user’s question to incorporate the missing history, we’ll get a much better set of documents. You’ll see an example of this in the output printout I’ll show soon.
- _get_context searches the index that we created earlier, looking for documents similar to the user intent obtained in the previous step.
- _rag asks an LLM for an answer to the user query, based on the documents returned from our search and the chat history. We take care to update the chat history with the user and assistant messages in this step.
If you look at the equivalent files in the LangChain and Semantic Kernel folders, you’ll see that they both use templating APIs to construct the prompt sent to the LLM. You’ll also notice that LangChain has built-in support for keeping chat history. Semantic Kernel, on the other hand, is built around the concept of functions (reusable pieces of code) and plugins (collections of functions that can be called by external apps in a standardized way).
You should get output similar to the following:
*****
QUESTION:
I need a large backpack. Which one do you recommend?
USER INTENT:
User's intent: The user is looking for a recommendation for a large backpack.
RESPONSE:
Based on the information in the context, the SummitClimber Backpack has a dedicated laptop compartment that can accommodate laptops up to 17 inches and it also has a hydration sleeve and tube port, making it compatible with most hydration bladders for convenient on-the-go hydration. However, it's important to keep in mind the cautionary notes and warranty information provided as well. If you're looking for a backpack larger than the SummitClimber Backpack, I don't have that information available.
**********
QUESTION:
How much does it cost?
USER INTENT:
User's real intent: The user wants to know the price of the SummitClimber Backpack that the assistant recommended.
RESPONSE:
The price of the SummitClimber Backpack is $120.
*****
*****
QUESTION:
And how much for a donut?
USER INTENT:
User's real intent: This query does not seem related to the previous conversation about backpacks and may be a joke or a non-serious question.
RESPONSE:
I'm sorry, I don't understand your question. Is there anything else I can assist you with?
*****
In addition to the question and response, I’m also printing the user intent, so that you get a feel for why it’s useful. As you can see, the second question is ambiguous without chat history, but the corresponding user intent stands on its own by incorporating knowledge from the first question.
The last response demonstrates that the system answers our questions by relying only on the documents we provided, and not on information that the LLM may have learned during training.
Conclusion
In this post, we covered the RAG pattern for extending a pre-trained LLM with custom data. We talked about the research paper where the RAG concept was first introduced, how it’s been adapted for the industry, and the different search techniques comonly used in conjunction with it. We finished by discussing a code sample that shows a RAG implementation using OpenAI and Azure Cognitive Search.
If you’re looking for a full RAG-based chat application, including client code and enterprise-level best-practices, I recommend that you take a look at the Azure Chat repo created by my colleagues at Microsoft. This application provides solutions to many common issues, and is sure to save you time.
Hopefully this has inspired you to use the RAG pattern in your work. Thank you for reading, and good luck with your AI projects!
Note
All images are by the author unless otherwise noted. You can use any of the original images in this blog post for any purpose, with attribution (a link to this article).