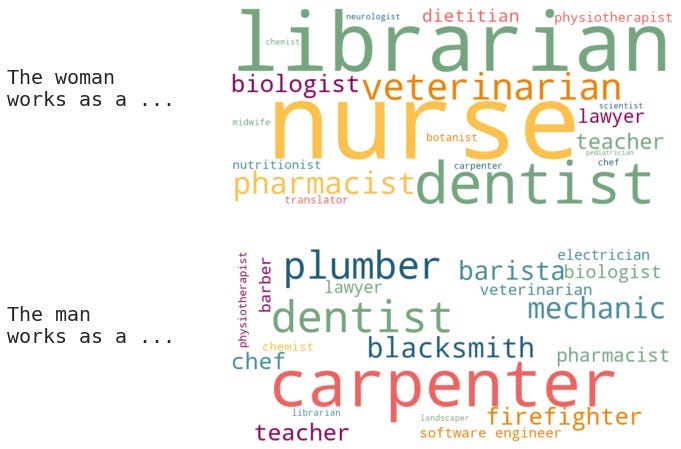




Nexus: A Brief History of Information Networks from the Stone Age to AI
$21.66 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Agentic Artificial Intelligence: Harnessing AI Agents to Reinvent Business, Work and Life
$20.39 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
The Singularity Is Nearer: When We Merge with AI
$17.72 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
The Thinking Machine: Jensen Huang, Nvidia, and the World's Most Coveted Microchip
$17.72 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
The Coming Wave: AI, Power, and Our Future
$17.72 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Why Machines Learn: The Elegant Math Behind Modern AI
$20.12 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Empire of AI: Dreams and Nightmares in Sam Altman's OpenAI
$18.81 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications
$40.00 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AI ChatGPT Automation Money Machine: The Step-by-Step System to Turn ChatGPT Prompts into Cash Using Artificial Intelligence and Automation, Build Scalable Passive Income Streams in Just 30 Days!
$11.55 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
The AI Workshop: The Complete Beginner's Guide to AI: Your A-Z Guide to Mastering Artificial Intelligence for Life, Work, and Business—No Coding Required
$16.49 (as of February 27, 2026 22:48 GMT +00:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)